|
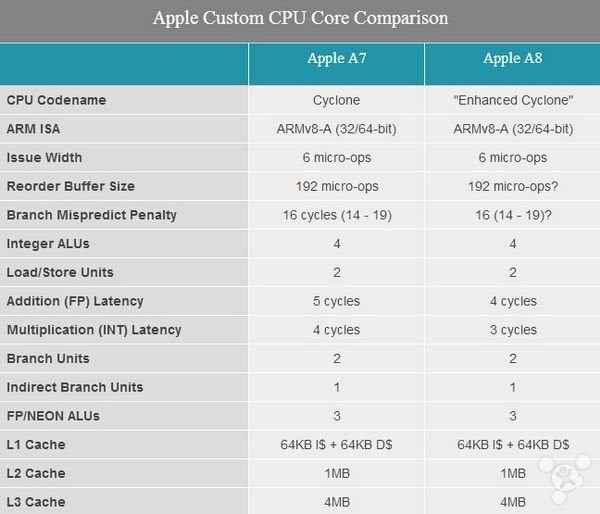
���x�O�����T��ÿ�ΰl����iPhone�ĕr��o�������µ� SoC��ϵ�y��оƬ��ȡ�����@һ��Ҳ�����⡣�S��iPhone6ϵ�еİl�����O��ӭ���������ĵڰ˴� SoC��Ҳ���� A8����ô�O��iPhone6��ô��... �O�����T��ÿ�ΰl����iPhone�ĕr��o�������µ� SoC��ϵ�y��оƬ��ȡ�����@һ��Ҳ�����⡣�S��iPhone6ϵ�еİl�����O��ӭ���������ĵڰ˴� SoC��Ҳ���� A8����ô�O��iPhone6��ô�ӣ�����С���͞��Ҏ���ʷ����ȫ�挣�I�u�y��һƪ���¾����㿴iPhone6�� �� A6 �� A7 �� SoC �Ŀ��ٸ�����--�քe�Ƴ����O���ĵ�һ��Ƶ� CPU �OӋ��Swift���͵�һ����� ARMv8 AArch 64 ���OӋ��Cyclone �ܘ�����A8 �@��оƬ���߽Y���Բ������O�� SoC �OӋ���ֱ�ӵ��w�F���@�����f�O���]�л��r�g�����M�������OӋ�����ܺ��ġ�ֻ�ǽ��^�^�죬�҂��l�F�� A8 �в��]���ҵ���� A6 �� A7 �ǘӵďص�׃����
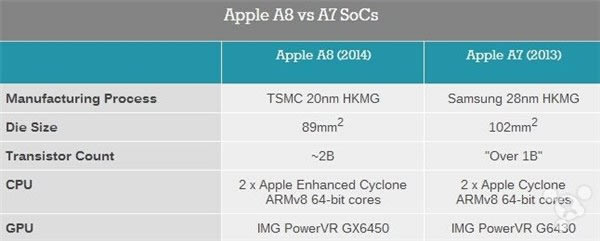
���O����20nm��A8 A8 �����K���`����Ȼ�� CPU �� GPU���҂��Ժ�����@�ɂ������M�и����w�ķ��������҂������f�@�ɂ����涼Ҫ�� A7 �����M�����O������� GPU ��Ȼ�x���� Imagination �� PowerVR������Ļ��� G6430 �� Series6 ϵ���������˸��µ� GX6450 �OӋ��ͬ�r�O���^�m�_�l�����Լҵ� CPU��A8 Ҳ���������µ��OӋ���@��һ��������Ļ��� A7 Cyclone �ܘ��ĺ��ġ�
�˕r�҂������Ȓ��_ GPU �� CPU��A8 ���ĸ�׃�����w�e��С�ˡ����� Chipworks �IJ���@ʾ��A8 �������_�e��µ� 20nm �Ƴ̹�ˇ���@ʹ�� iPhone 6 �ɞ��һ����� 20nm �Ƴ� SoC �������֙C�� ʹ�� 20nm �Ƴ̵Ĺ�ˇ�҂��������⣬���M������҂�߀��Ҫ����һ����ԭ�����ȣ��@��ζ���O���ѽ������a�D�Ƶ��_�e늵� 20nm HKMG Planar���߽�늽����l�Oƽ�棩���a��ˇ���@ʹ���O���� SoC ��һ���������@�N���a��ˇ������֮��߀�кܶ���ܵ�����--��������ÿһ�����ɶ��Ǽ��g����ģ��������a�lչ�ĽǶȁ������_�e�һֱ���^ȥ�״� SoC �aƷ���a���I�^�����S���@ʹ�������ɞ��һ�ҿ���ʹ���@�N��ˇ��� SoC �M�����a�Ĺ�˾��
���eֵ�ÿ��]߀����@��ζ���O���״�ʹ���@�N�д���C�Ĺ�ˇ��������� SoC ���a���ڴ�֮ǰ�O������ʹ���µ����a��ˇ�IJ���һֱ����죬ֱ��ȥ������������_ʼʹ�� 28nm �Ƴ̵ļ��g��� A7 �M�����a�����@���x 28nm �Ƴ̵ļ��g�����ѽ����^һ���ˡ� ���ʹ�� 20nm �Ƴ̵Ĺ�ˇҲ�Ǻ�����˼��һ���£����֮ǰ�Ď״���ˇ����“���S�M”ʽ���� 45nm �� 40nm �� 32nm �� 28nm������ 28nm һ�������� 20nm �t���J����“ȫ�S�M”���O���]�����^ 40nm�����@��ζ���҂����������ھ��w���ܶȼ��g����ľ��S�M������Փ�ρ�����Ҳ���Կ����ǹ��ĵľ�p�١� �����_�e늵� 20nm ��ˇ����һ�����s�Z������� 28nm �Ƴ̵Ĺ�ˇ�������ṩ 30%�ļ��٣��ܶ����� 1.9 �������߹��Ĝp�� 25%�������ǹ��ĺ��ٶȌ�������ֱ�ӵ��w�F���κεĸ����l�������ĵĸ��M�������@�������DZ��^�����Ǻ��_�e늵� SoC �ĕr�� �����]�_�e늺�����ֱ�ӵ�С��e��Ԓ����������r���O�������� 51%�ą^��y�������ڌ��H��r�£��ܶȌ�ȡ�Q�� I/C ���O������������������оƬ���f 60-70%�ı���ϵ����������Ǹ��õĴ��Թ��㡣���ε��f�������O�����f���ǫ@���˸��������¹��ܵĿ��g�͜p����оƬ�Ŀ��w��e��
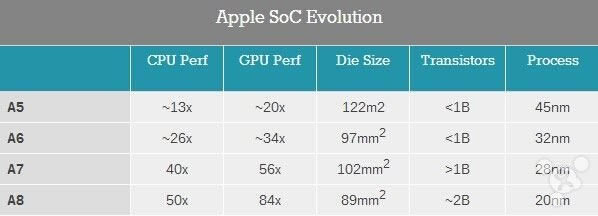
�c��ͬ�r�O��������һ�εع��_��оƬ����e�;��w�ܵĔ�����A8 ��s�� 20 �|�����w�ܣ��c֮�������� A7 ��“���^ 10 �|��”--89 ƽ��������e���@�� A7 �� 102 ƽ�����לp���� 13%���@�C���O���x�������ӹ���/���ܺ͜p�ٴ�С֮�g�x���˷��x���w�ܵ��ܶȣ������Ǽ�����һ�� �����f��ʹ�� 20nm �Ƴ̵Ĺ�ˇ��һ���õ����⣬������O�����_�e���Ҫ̎���� 20nm оƬ�����ʵĆ��}��20nm �����ʛ]�� 28nm �ĸߣ������ʲ��ߵ���r�£���С�͵�оƬ��e���Խ������a�^���е�覴Á�����һЩ���ʎ����ēpʧ���Ķ���߿��w�����ʡ�
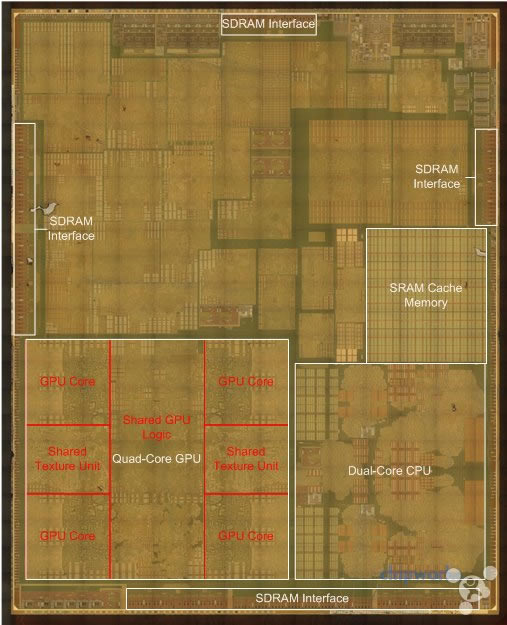
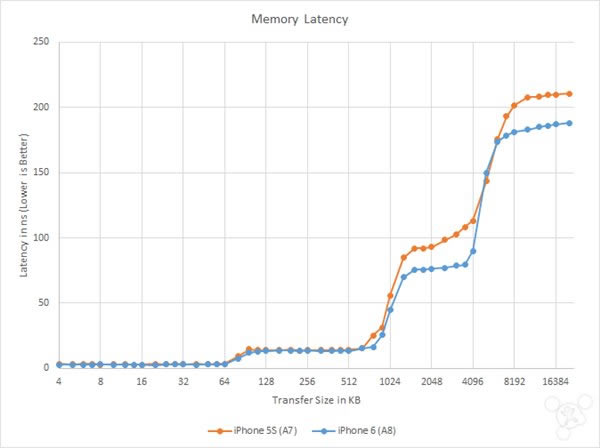
�� A8 ��ӛ���w��ϵ�y������OӋ��� A7 ���]���@����׃�����O����һ����оƬ�Ϸ����� SRAM ������ CPU �� GPU ���ա����ڌ�оƬ�����t���ęz�y��L3 SRAM ������Ȼ�� A7 ��һ�ӣ�ͣ���� 4MB��ͬ�r�҂��l�Fһϵ�е� SDRAM �ӿ�ʹ�� A8 �� POP ���ѯB���b����Ȼ�������ȴ档�� iFixit �IJ��ɰl�F���O����Ȼʹ��LPDDR3-1600��1GB�ȴ棬�@�� LPDDR3 ����ͬһ���ٶȼ��e��iFixit ߀�l�F Hynix �� Elpida �ăȴ���F���֙C�У��@�C���O����һ��ʹ�ò�ͬ�����̵� RAM���ȴ棩�� ���ȴ控�����棬�҂��l�F A8 �ăȴ控��Ҫ���� A7 ʹ�õĸߣ������������@���Կ����O��ԇ�D���õ،��ȴ控���M�Ѓ�����
���� Stream Copy �ĵ÷��@ʾ���ȴ控������������_ 9%����������һЩ�ܷքt�@ʾ�ȴ控��ֻ������ 2-3%�� ����Ȥ���ǃȴ�����t��r�������@ʾ��һЩ�҂��� L1 �� L2 ����ó������벻���ĸ��M�������ȴ�� SRAM �� 6MB+�^��� 1MB-4MB �ķ����ȣ��ȴ�����t�� A8 �ϳ��m���ͣ����� A7�����@�ɷN��r�£�20ns �����t�� A7 Ҫ�졣��ȫһ�ӵ� 20ns ���Ӹ��V�҂��O������ L3 ��߉ֵ���M�����ȴ��߉ֵ���ң����^��Ҳ���� 20ns �ī@�������� L3 ����ă�����
�@�� A8 ��оƬ����e��Ҫ���� CPU��GPU �� SRAM �M�ɣ�����Ŀ��g�t���O��һЩ���ϵ��OӋ����ռ������Ŀǰ�҂����y�l�F�@Щ�^����������ʲô�|�������҂������@���аl�F���l��������USB ��������ҕ�l���a/��a�����W������������C ISP ���N���ӵľ��� �����е��@Щ�^���w���̶����ܵ�Ӳ�����@���H���� A8 �Ĺ���ʮ����Ҫ���������ܺĵĿ���Ҳ�Ƿdz��P�I�ġ�ͨ�^�����΄յ��ض���Ӳ�����O�����ڴ˻��Mһ�c��e������֮�@Щ�^�������������ܛ���ϸ���Ч�ʡ�����O��������“�әC”��ж���M���ܶ���΄Ձ����ֹ��ĵ�ƽ�⡣
�������ӣ��M���҂��o�����J�� A8 оƬ��ÿһ���^��ؓ؟ʲô�Ĺ��ܣ����҂�����֪���O�����@Щ�^���������µĹ��ܡ����@����֮һ���nj��� H.265��ҕ�l���a�������ϣ��@����ʹ�� H.265 ���܁��_�� FaceTime �ȹ��ܷdz���Ҫ�� ���_A8�����漆 A8 CPU��Cyclone ֮����ʲô�� �mȻ�����O���� SoC��Ƭ��ϵ�y���OӋ���f CPU �Ƿdz���Ҫ��һ�h������˾����ܘ����ؿ���ƿ֮�̶�߀�Ƿdz��˳��@���M���O����Ϳ����� CPU ���䪚���OӋ�еĵ�λ�������@�����{�v�ăɂ��ܘ����oՓ��һ���ļ��g����������Ȼ����Մ�����ܲ��ң��@�F����һ�������_ʼ���������ڵ� SoC ���f������أ�A8 Ҳ�����⡣ ���ā��f�����܉�_������ A8 �c A7 ��ț]��̫��IJ�֮ͬ̎�����@������һ�����¡��� Cyclone �ܘ��Ď������O���ߵú܈Ԍ���IPC �OӋ�^�����^�ߣ����t�ͣ������ںܵ͵��l����ȡ�úܸߵ����ܡ����@�N�OӋ˼·�£��O���Ϳ����ڱ��C�ܺ����͵�ǰ�����_���Լ������ܘ˜ʡ��@�c�����������ƣ����]�÷dz���ȫ�����⣬���� Cyclone ���OӋ�dz�����ǰհ�ԣ��������ṩ AArch64 ���Р�B�� ARMv8 �����������ѽ�׃�ú�������O���Ͳ���Ҫ�����挦�ص��¼ܘ��ĉ������� ARMv7 �Ͳ����@���ˡ�
�����Ϸ������õ��ĽYՓ�ǣ�A8 ��֮ǰ�� Cyclone �]�б��|�ϵą^�e��A8 �϶����H�H�Ǹ��l��� Cyclone ���ѣ������� Cyclone ������ Swift �ĸ��������ߵIJ��ͺ�С�ˡ� ��ϧ�����O������ A8 �ı��̶ܳȿ����f�ǿ�ǰ�ĸߣ���ˁ��Թٷ�����Ϣ��֮���٣������B�µļܘ����Q����֪����ֻ�܌����Q�� Enhanced Cyclone���ӏ��� Cyclone������Ȼ Enhanced Cyclone ֻ�nj��¼ܘ���һ�N�������ѣ��O���Ȳ����˅^�ֿ϶�߀���µ�������ϣ�����Ժ�������� ������ô�f���܉�_������ Enhanced Cyclone ���c�����O�����L��оƬ�ڏ� 28nm �� A7 �Q�� 20nm �� A8 �Ժ�׃�ñ���ǰС�öࡣA8 CPU ���ֵ���e�s�� 12.2 ƽ�����ף��^֮ A7 �� 17.1 ƽ�����לpС�� 29%����ʹ�@������������֔��Ҳ�����f�� A8 �������˸��ྦྷ�w��֮����e������С�ˡ��M�� A8 �ľ��w�ܔ��������� A7 ����٣����@�����f���� Cyclone ֮���O���Ĺ�ˇ���M���ˡ� ��ô���}���ˣ��O�����@����ľ��w�ܺ�ʡ���Ŀ��g����ʲôȥ�ˣ�һ���ֿ϶����õ��˴惦���ӿ��ϣ���� L3 cache ���L���r�g�ڜyԇ�б�֮ǰ���� 20 ���롣�S���l������룬����׃�ø�����Ȥ�ˡ�
���ȣ��ڶ�Μyԇ�� Enhanced Cyclone �ı��F�ͺ� Cyclone �dz����ơ��m�f A8 ���l���� 1.4GHz �� A7 �� 1.3GHz�����S��Ӝyԇ���������F�þͺ���ͬһ�wоƬ���Ĕ����������ߛ]�б��|�ϵIJ�ͬ��Enhanced Cyclone ���f��һ�������^�� IPC ����ָ��ܘ�������֧�A�y�e�`�pʧҲ����
��һ�12 3 4 5 6 7 8 ��һ� ��xȫ��
|
��ܰ��ʾ��ϲ�g��վ��Ԓ��Ո�ղ�һ�±�վ��
��վ�l����Win7������ϵ�y��Win10�������XP������ϵ�y�H�邀�ˌW���yԇʹ�ã�Ո�����d��24С�r�Ȅh�������������κ��̘I��;����t�����ؓ��Ո֧��ُ�Iܛ����ܛ����
��վ�����YԴȫ�������ھW�j�YԴ,���ַ������ę���,Ո���r֪ͨ�҂�([email protected]),�҂������r̎��.
Copyright © 2018-2020 ����ľ�L���dվ